
I am now working at HeyGen ![]() , leading foundation video model research team at the Singapore office. If you are seeking any form of academic cooperation, please feel free to email me at rayeren613@gmail.com. We are hiring interns!
, leading foundation video model research team at the Singapore office. If you are seeking any form of academic cooperation, please feel free to email me at rayeren613@gmail.com. We are hiring interns!
I graduated from Chu Kochen Honors College, Zhejiang University (浙江大学竺可桢学院) with a bachelor’s degree and from the Department of Computer Science and Technology, Zhejiang University (浙江大学计算机科学与技术学院) with a master’s degree, advised by Zhou Zhao (赵洲). I also collaborate with Xu Tan (谭旭), Tao Qin (秦涛) and Tie-yan Liu (刘铁岩) from Microsoft Research Asia closely.
I won the Baidu Scholarship (10 candidates worldwide each year) and ByteDance Scholars Program (10 candidates worldwide each year) in 2020 and was selected as one of the top 100 AI Chinese new stars and AI Chinese New Star Outstanding Scholar (10 candidates worldwide each year).
My research interest includes speech synthesis, neural machine translation and automatic music generation. I have published 50+ papers 
To promote the communication among the Chinese ML & NLP community, we (along with other 11 young scholars worldwide) founded the MLNLP community in 2021. I am honored to be one of the chairs of the MLNLP committee.
If you like the template of this homepage, welcome to star and fork my open-sourced template version AcadHomepage 
🔥 News
- 2024.03: 🎉 Two papers are accepted by ICLR 2024
- 2023.05: 🎉 Five papers are accepted by ACL 2023
- 2023.01: DiffSinger was introduced in a very popular video (2000k+ views) in Bilibili!
- 2023.01: I join TikTok
 as a speech research scientist in Singapore!
as a speech research scientist in Singapore! - 2022.02: I release a modern and responsive academic personal homepage template. Welcome to STAR and FORK!
📝 Publications
🎙 Speech Synthesis
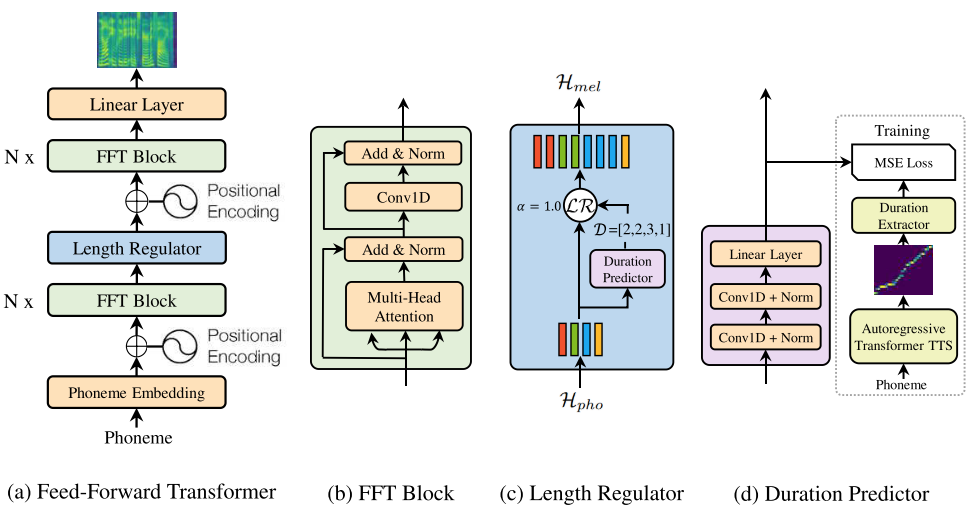
FastSpeech: Fast, Robust and Controllable Text to Speech
Yi Ren, Yangjun Ruan, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, Tie-Yan Liu
- FastSpeech is the first fully parallel end-to-end speech synthesis model.
- Academic Impact: This work is included by many famous speech synthesis open-source projects, such as ESPNet
. Our work are promoted by more than 20 media and forums, such as 机器之心、InfoQ.
- Industry Impact: FastSpeech has been deployed in Microsoft Azure TTS service and supports 49 more languages with state-of-the-art AI quality. It was also shown as a text-to-speech system acceleration example in NVIDIA GTC2020.
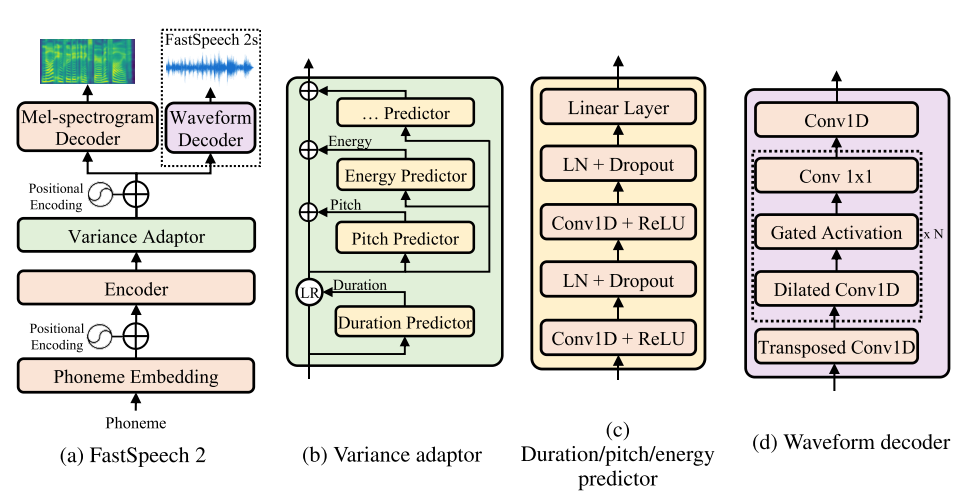
FastSpeech 2: Fast and High-Quality End-to-End Text to Speech
Yi Ren, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, Tie-Yan Liu
- This work is included by many famous speech synthesis open-source projects, such as PaddlePaddle/Parakeet
, ESPNet
.
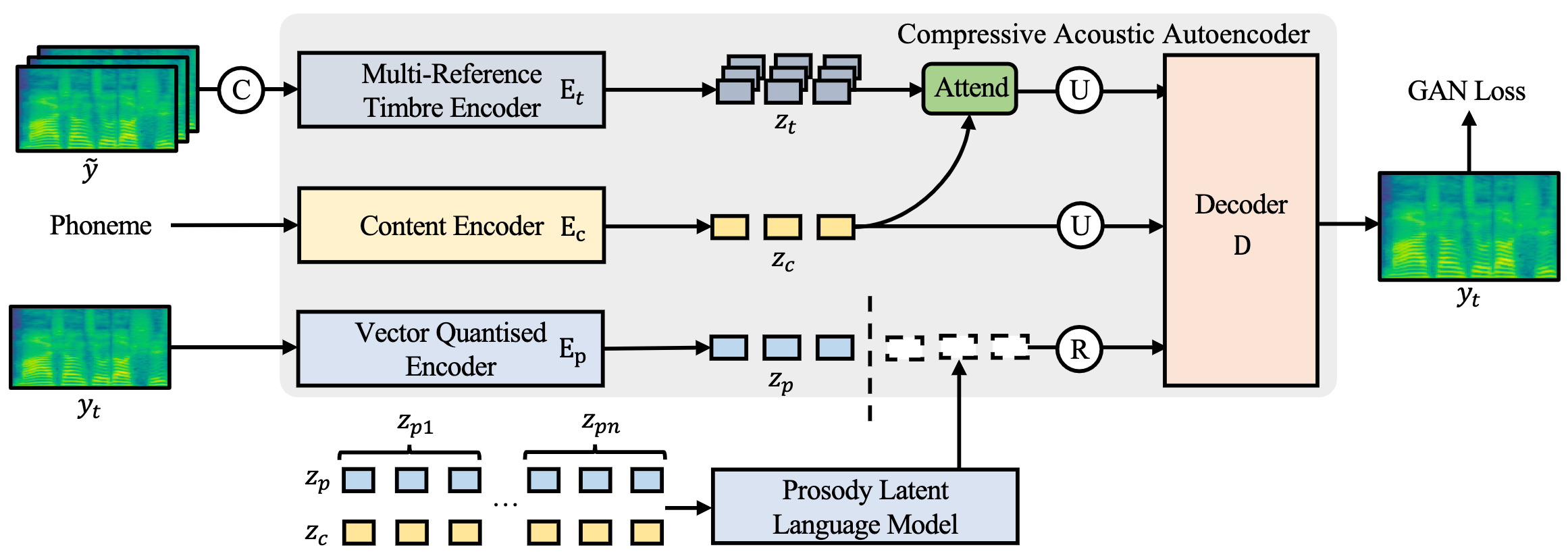
Mega-TTS 2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis \ Ziyue Jiang, Jinglin Liu, Yi Ren, et al.
- This work has been deployed on many TikTok products.
- Advandced zero-shot voice cloning model.
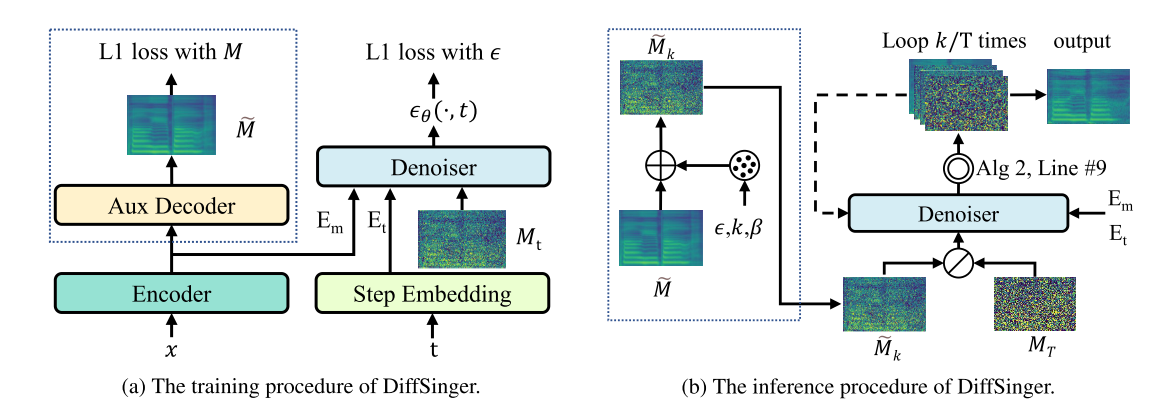
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism
Jinglin Liu, Chengxi Li, Yi Ren, Feiyang Chen, Zhou Zhao
- Many video demos created by the DiffSinger community are released.
-
DiffSinger was introduced in a very popular video (1600k+ views) on Bilibili!
- Project |
|
|
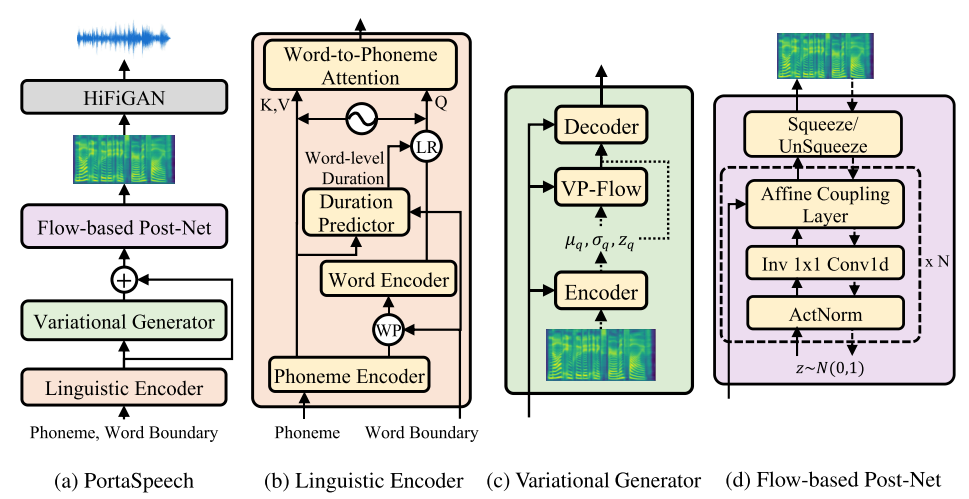
PortaSpeech: Portable and High-Quality Generative Text-to-Speech
Yi Ren, Jinglin Liu, Zhou Zhao
Project | 
ACL Findings 2025Chain-Talker: Chain Understanding and Rendering for Empathetic Conversational Speech Synthesis, Yifan Hu, Rui Liu, Yi Ren, Xiang Yin, Haizhou LiarXiv 2025MegaTTS 3: Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis, Ziyue Jiang, Yi Ren, et al.ACM-MM 2024Generative Expressive Conversational Speech Synthesis, Rui Liu, Yifan Hu, Yi Ren, Xiang Yin, Haizhou LiAAAI 2024AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head, Rongjie Huang, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, Yi Ren, Zhou Zhao, Shuicheng YanAAAI 2024Emotion Rendering for Conversational Speech Synthesis with Heterogeneous Graph-Based Context Modeling, Rui Liu, Yifan Hu, Yi Ren, et al.ICML 2023Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models, Rongjie Huang, Jiawei Huang, Dongchao Yang, Yi Ren, et al.ACL 2023CLAPSpeech: Learning Prosody from Text Context with Contrastive Language-Audio Pre-Training, Zhenhui Ye, Rongjie Huang, Yi Ren, et al.ACL 2023FluentSpeech: Stutter-Oriented Automatic Speech Editing with Context-Aware Diffusion Models, Ziyue Jiang, Qian Yang, Jialong Zuo, Zhenhui Ye, Rongjie Huang, Yi Ren and Zhou ZhaoACL 2023Revisiting and Incorporating GAN and Diffusion Models in High-Fidelity Speech Synthesis, Rongjie Huang, Yi Ren, Ziyue Jiang, et al.ACL 2023Improving Prosody with Masked Autoencoder and Conditional Diffusion Model For Expressive Text-to-Speech, Rongjie Huang, Chunlei Zhang, Yi Ren, et al.ICLR 2023Bag of Tricks for Unsupervised Text-to-Speech, Yi Ren, Chen Zhang, Shuicheng YanINTERSPEECH 2023StyleS2ST: zero-shot style transfer for direct speech-to-speech translation, Kun Song, Yi Ren, Yi Lei, et al.INTERSPEECH 2023GenerTTS: Pronunciation Disentanglement for Timbre and Style Generalization in Cross-Lingual Text-to-Speech, Yahuan Cong, Haoyu Zhang, Haopeng Lin, Shichao Liu, Chunfeng Wang, Yi Ren, et al.NeurIPS 2022Dict-TTS: Learning to Pronounce with Prior Dictionary Knowledge for Text-to-Speech, Ziyue Jiang, Zhe Su, Zhou Zhao, Qian Yang, Yi Ren, et al.NeurIPS 2022GenerSpeech: Towards Style Transfer for Generalizable Out-Of-Domain Text-to-Speech, Rongjie Huang, Yi Ren, et al.NeurIPS 2022M4Singer: a Multi-Style, Multi-Singer and Musical Score Provided Mandarin Singing Corpus, Lichao Zhang, Ruiqi Li, Shoutong Wang, Liqun Deng, Jinglin Liu, Yi Ren, et al. (Datasets and Benchmarks Track)ACM-MM 2022ProDiff: Progressive Fast Diffusion Model for High-Quality Text-to-Speech, Rongjie Huang, Zhou Zhao, Huadai Liu, Jinglin Liu, Chenye Cui, Yi Ren,ACM-MM 2022SingGAN: Generative Adversarial Network For High-Fidelity Singing Voice Generation, Rongjie Huang, Chenye Cui, Chen Feiayng, Yi Ren, et al.IJCAI 2022SyntaSpeech: Syntax-Aware Generative Adversarial Text-to-Speech, Zhenhui Ye, Zhou Zhao, Yi Ren, et al.IJCAI 2022(Oral) EditSinger: Zero-Shot Text-Based Singing Voice Editing System with Diverse Prosody Modeling, Lichao Zhang, Zhou Zhao, Yi Ren, et al.IJCAI 2022FastDiff: A Fast Conditional Diffusion Model for High-Quality Speech Synthesis, Rongjie Huang, Max W. Y. Lam, Jun Wang, Dan Su, Dong Yu, Yi Ren, Zhou Zhao, (Oral),NAACL 2022A Study of Syntactic Multi-Modality in Non-Autoregressive Machine Translation, Kexun Zhang, Rui Wang, Xu Tan, Junliang Guo, Yi Ren, et al.ACL 2022Revisiting Over-Smoothness in Text to Speech, Yi Ren, Xu Tan, Tao Qin, et al.ACL 2022Learning the Beauty in Songs: Neural Singing Voice Beautifier, Jinglin Liu, Chengxi Li, Yi Ren, et al. |ICASSP 2022ProsoSpeech: Enhancing Prosody With Quantized Vector Pre-training in Text-to-Speech, Yi Ren, et al.INTERSPEECH 2021EMOVIE: A Mandarin Emotion Speech Dataset with a Simple Emotional Text-to-Speech Model, Chenye Cui, Yi Ren, et al.INTERSPEECH 2021(best student paper award candidate) WSRGlow: A Glow-based Waveform Generative Model for Audio Super-Resolution, Kexun Zhang, Yi Ren, Changliang Xu and Zhou ZhaoICASSP 2021Denoising Text to Speech with Frame-Level Noise Modeling, Chen Zhang, Yi Ren, Xu Tan, et al. | ProjectACM-MM 2021Multi-Singer: Fast Multi-Singer Singing Voice Vocoder With A Large-Scale Corpus, Rongjie Huang, Feiyang Chen, Yi Ren, et al. (Oral)IJCAI 2021FedSpeech: Federated Text-to-Speech with Continual Learning, Ziyue Jiang, Yi Ren, et al.KDD 2020DeepSinger: Singing Voice Synthesis with Data Mined From the Web, Yi Ren, Xu Tan, Tao Qin, et al. | ProjectKDD 2020LRSpeech: Extremely Low-Resource Speech Synthesis and Recognition, Jin Xu, Xu Tan, Yi Ren, et al. | ProjectINTERSPEECH 2020MultiSpeech: Multi-Speaker Text to Speech with Transformer, Mingjian Chen, Xu Tan, Yi Ren, et al. | ProjectICML 2019(Oral) Almost Unsupervised Text to Speech and Automatic Speech Recognition, Yi Ren, Xu Tan, Tao Qin, et al. | Project







👄 TalkingFace & Avatar
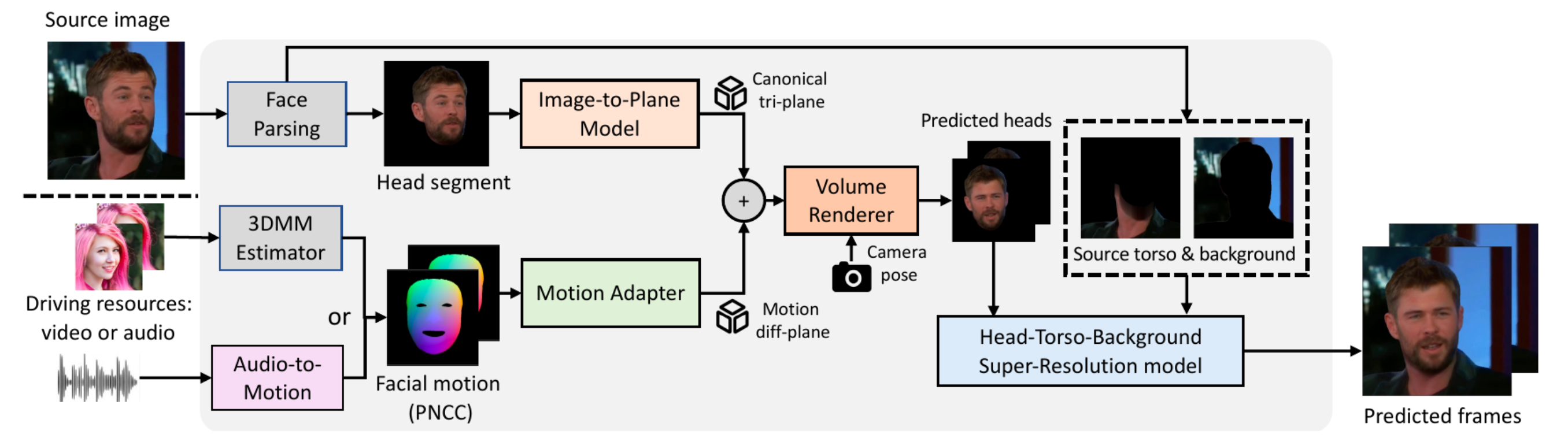
Real3D-Portrait: One-shot Realistic 3D Talking Portrait Synthesis, Zhenhui Ye, Tianyun Zhong, Yi Ren, et al. (Spotlight) Project | Code
NeurIPS 2024MimicTalk: Mimicking a Personalized and Expressive 3D Talking Face in Minutes, Zhenhui Ye, Tianyun Zhong, Yi Ren, et al.ACM-MM 2025UniTalker: Conversational Speech-Visual Synthesis, Yifan Hu, Rui Liu, Yi Ren, Xiang Yin, Haizhou LiarXiv 2025HumanDiT: Pose-guided Diffusion Transformer for Long-form Human Motion Video Generation, Qijun Gan, Yi Ren, et al.arXiv 2025InfinityHuman: Towards Long-Term Audio-Driven Human, Xinran Li, Peiqi Xie, Yi Ren, et al.ICLR 2023GeneFace: Generalized and High-Fidelity Audio-Driven 3D Talking Face Synthesis, Zhenhui Ye, Ziyue Jiang, Yi Ren, et al.AAAI 2024AMD: Autoregressive Motion Diffusion, Bo Han, Hao Peng, Minjing Dong, Yi Ren, et al.AAAI 2022Parallel and High-Fidelity Text-to-Lip Generation, Jinglin Liu, Zhiying Zhu, Yi Ren, et al. |AAAI 2022Flow-based Unconstrained Lip to Speech Generation, Jinzheng He, Zhou Zhao, Yi Ren, et al.ACM-MM 2020FastLR: Non-Autoregressive Lipreading Model with Integrate-and-Fire, Jinglin Liu, Yi Ren, et al.

📚 Machine Translation
Interspeech 2024A Unit-based System and Dataset for Expressive Direct Speech-to-Speech Translation, Ao Min, Chenxu Hu, Yi Ren, Hai ZhaoACL 2023AV-TranSpeech: Audio-Visual Robust Speech-to-Speech Translation, Rongjie Huang, Huadai Liu, Xize Cheng, Yi Ren, et al.ICLR 2023TranSpeech: Speech-to-Speech Translation With Bilateral Perturbation, Rongjie Huang, Jinglin Liu, Huadai Liu, Yi Ren, Lichao Zhang, Jinzheng He, Zhou ZhaoAAAI 2021UWSpeech: Speech to Speech Translation for Unwritten Languages, Chen Zhang, Xu Tan, Yi Ren, et al. | ProjectIJCAI 2020Task-Level Curriculum Learning for Non-Autoregressive Neural Machine Translation, Jinglin Liu, Yi Ren, Xu Tan, et al.ACL 2020SimulSpeech: End-to-End Simultaneous Speech to Text Translation, Yi Ren, Jinglin Liu, Xu Tan, et al.ACL 2020A Study of Non-autoregressive Model for Sequence Generation, Yi Ren, Jinglin Liu, Xu Tan, et al.ICLR 2019Multilingual Neural Machine Translation with Knowledge Distillation, Xu Tan, Yi Ren, Di He, et al.
🎼 Music & Dance Generation
CVM 2024Dance2MIDI: Dance-driven Multi-instrument Music Generation, Bo Han, Yuheng Li, Yixuan Shen, Yi Ren, Fei HanIEEE TMMSDMuse: Stochastic Differential Music Editing and Generation via Hybrid Representation, Chen Zhang, Yi Ren, Kejun Zhang, Shuicheng Yan.AAAI 2021SongMASS: Automatic Song Writing with Pre-training and Alignment Constraint, Zhonghao Sheng, Kaitao Song, Xu Tan, Yi Ren, et al.ACM-MM 2020(Oral) PopMAG: Pop Music Accompaniment Generation, Yi Ren, Jinzheng He, Xu Tan, et al. | Project
🧑🎨 Generative Model
ICLR 2022Pseudo Numerical Methods for Diffusion Models on Manifolds, Luping Liu, Yi Ren, Zhijie Lin, Zhou Zhao ||

Others
NeurIPS 2023Unsupervised Video Domain Adaptation for Action Recognition: A Disentanglement Perspective, Pengfei Wei, Lingdong Kong, Xinghua Qu, Yi Ren, et al.ACM-MM 2022Video-Guided Curriculum Learning for Spoken Video Grounding, Yan Xia, Zhou Zhao, Shangwei Ye, Yang Zhao, Haoyuan Li, Yi Ren
🎖 Honors and Awards
- 2021.10 Tencent Scholarship (Top 1%)
- 2021.10 National Scholarship (Top 1%)
- 2020.12 Baidu Scholarship (10 students in the world each year)
- 2020.12 AI Chinese new stars (100 worldwide each year)
- 2020.12 AI Chinese New Star Outstanding Scholar (10 candidates worldwide each year)
- 2020.12 ByteDance Scholars Program (10 students in China each year)
- 2020.10 Tianzhou Chen Scholarship (Top 1%)
- 2020.10 National Scholarship (Top 1%)
- 2015.10 National Scholarship (Undergraduate) (Top 1%)
📖 Educations
- 2019.06 - 2022.04, Master, Zhejiang University, Hangzhou.
- 2015.09 - 2019.06, Undergraduate, Chu Kochen Honors College, Zhejiang Univeristy, Hangzhou.
- 2012.09 - 2015.06, Luqiao Middle School, Taizhou.
💬 Invited Talks
- 2022.02, Hosted MLNLP seminar | [Video]
- 2021.06, Audio & Speech Synthesis, Huawei internal talk
- 2021.03, Non-autoregressive Speech Synthesis, PaperWeekly & biendata | [video]
- 2020.12, Non-autoregressive Speech Synthesis, Huawei Noah’s Ark Lab internal talk
💻 Internships
- 2021.06 - 2021.09, Alibaba, Hangzhou.
- 2019.05 - 2020.02, EnjoyMusic, Hangzhou.
- 2019.02 - 2019.05, YiWise, Hangzhou.
- 2018.08 - 2019.02, MSRA, machine learning Group, Beijing.
- 2018.01 - 2018.06, NetEase, AI department, Hangzhou.
- 2017.08 - 2018.12, DashBase (acquired by Cisco), Hangzhou.